加速当今时代的重要工作
NVIDIA A100 Tensor Core GPU 可针对 AI、数据分析和 HPC 应用场景,在不同规模下实现出色的加速,有效助力全球高性能弹性数据中心。NVIDIA A100 由 NVIDIA Ampere 架构提供支持,提供 40GB 和 80GB 两种配置。作为 NVIDIA 数据中心平台的引擎,A100 的性能比上一代产品提升高达 20 倍,并可划分为七个 GPU 实例,以根据变化的需求进行动态调整。A100 80GB 将 GPU 内存增加了一倍,提供超快速的内存带宽(每秒超过 2TB),可处理超大模型和非常庞大的数据集。
强大的端到端 AI 和 HPC 数据中心平台
A100 是完整 NVIDIA 数据中心解决方案的一部分,该解决方案结合了跨硬件、网络、软件、库以及 NGC™ 的经过优化的 AI 模型和应用程序的构建块。 它代表了强大的数据中心端到端 AI 和 HPC 平台,使研究人员可以提供真实的结果并将解决方案大规模部署到生产中。
深度学习训练
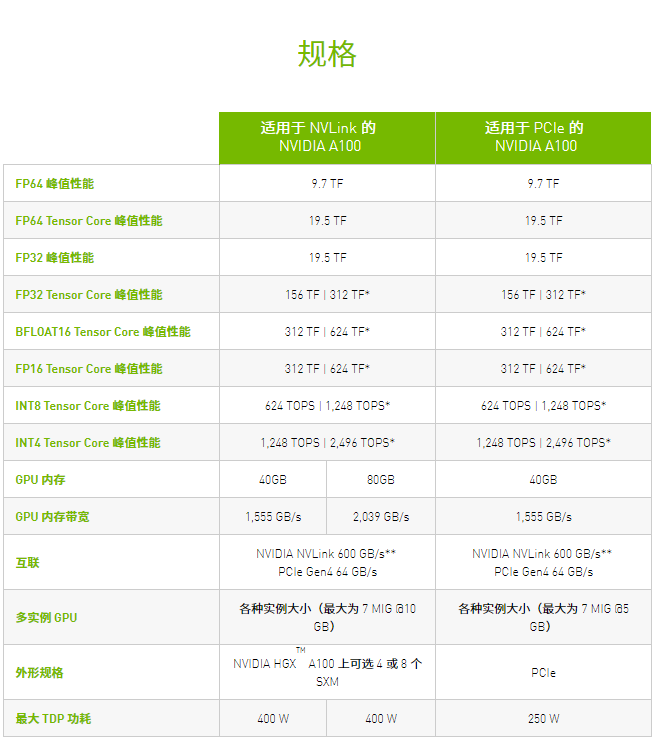
 HugeCTR 框架上的 DLRM,精度 = FP16 | NVIDIA A100 80GB 批量大小 = 48 | NVIDIA A100 40GB 批量大小 = 32 | NVIDIA V100 32GB 批量大小 = 32
HugeCTR 框架上的 DLRM,精度 = FP16 | NVIDIA A100 80GB 批量大小 = 48 | NVIDIA A100 40GB 批量大小 = 32 | NVIDIA V100 32GB 批量大小 = 32
当今的 AI 模型面临着对话式 AI 等更高层次的挑战,这促使其复杂度呈爆炸式增长。训练这些模型需要大规模的计算能力和可扩展性。
NVIDIA A100 的 Tensor Core 借助 Tensor 浮点运算 (TF32) 精度,可提供比上一代 NVIDIA Volta 高 20 倍之多的性能,并且无需更改代码;若使用自动混合精度和 FP16,性能可进一步提升 2 倍。与 NVIDIA® NVLink®、NVIDIA NVSwitch™、PCI 4.0、NVIDIA® Mellanox® InfiniBand® 和 NVIDIA Magnum IO™ SDK 结合使用时,可扩展到数千个 A100 GPU。
2048 个 A100 GPU 可在一分钟内大规模处理 BERT 之类的训练工作负载,这是训练时间的世界纪录。
对于具有庞大数据表的超大型模型(例如用于推荐系统的 DLRM),A100 80GB 可为每个节点提供高达 1.3 TB 的统一显存,而且速度比 A100 40GB 快高达 3 倍。
NVIDIA 产品的领先地位在 MLPerf 这个行业级 AI 训练基准测试中得到印证,创下多项性能纪录。
深度学习推理
A100 引入了突破性的功能来优化推理工作负载。它能在从 FP32 到 INT4 的整个精度范围内进行加速。多实例 GPU (MIG) 技术允许多个网络同时基于单个 A100 运行,从而优化计算资源的利用率。在 A100 其他推理性能增益的基础之上,仅结构化稀疏支持一项就能带来高达两倍的性能提升。
在 BERT 等先进的对话式 AI 模型上,A100 可将推理吞吐量提升到高达 CPU 的 249 倍。
在受到批量大小限制的极复杂模型(例如用于先进自动语音识别用途的 RNN-T)上,显存容量有所增加的 A100 80GB 能使每个 MIG 的大小增加一倍(达到 10GB),并提供比 A100 40GB 高 1.2 倍的吞吐量。
NVIDIA 产品的出色性能在 MLPerf 推理测试中得到验证。A100 再将性能提升了 20 倍,进一步扩大了这种性能优势。

高性能计算
为了获得新一代的发现成果,科学家们希望通过模拟方式来更好地了解我们周围的世界。
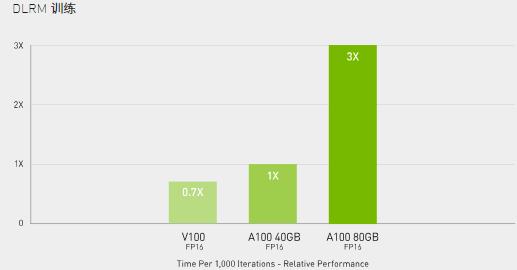
A100 的双精度 Tensor Core 为 HPC 领域带来了自 GPU 中的双精度计算技术推出以来极其重要的里程碑。借助 HBM2e 每秒超过 2 TB 的带宽和大容量内存,科研人员可以在 A100 上将原本要花费 10 小时的双精度模拟过程缩短到 4 小时之内。HPC 应用程序还可以利用 TF32 将单精度、密集矩阵乘法运算的吞吐量提高高达 10 倍。
对于具有超大型数据集的 HPC 应用程序,内存容量增加的 A100 80GB 可在运行材料模拟 Quantum Espresso 时将速度提升高达两倍。极大的内存容量和超快速的内存带宽使 A100 80GB 非常适合用作新一代工作负载的平台。
高性能数据分析
 数据科学家需要能够分析和可视化庞大的数据集,并将其转化为宝贵见解。但是,由于数据集分散在多台服务器上,横向扩展解决方案往往会陷入困境。
数据科学家需要能够分析和可视化庞大的数据集,并将其转化为宝贵见解。但是,由于数据集分散在多台服务器上,横向扩展解决方案往往会陷入困境。
搭载 A100 的加速服务器可以提供必要的计算能力,并能利用大容量内存以及通过 NVIDIA® NVLink® and NVSwitch™ 实现的超快速内存带宽(超过每秒 2 TB)和可扩展性妥善处理工作负载。通过结合 InfiniBand, NVIDIA Magnum IO™ 和 RAPIDS™ 开源库套件(包括用于执行 GPU 加速的数据分析的 RAPIDS Accelerator for Apache Spark),NVIDIA 数据中心平台能够加速这些大型工作负载,并实现超高的性能和效率水平。
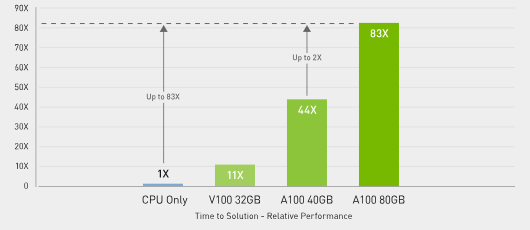
在大数据分析基准测试中,A100 80GB 的速度比 CPU 快 83 倍,并且比 A100 40GB 快两倍,因此非常适合处理数据集大小激增的新型工作负载。
企业就绪,高效利用
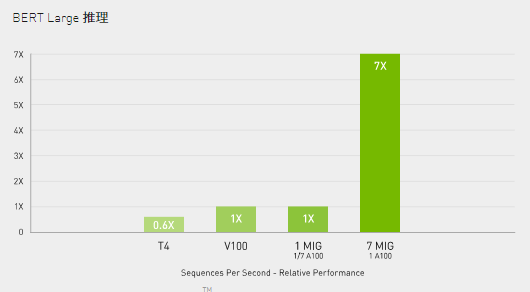 A100 结合 MIG 技术可以更大限度地提高 GPU 加速的基础设施的利用率。借助 MIG,A100 GPU 可划分为多达 7 个独立实例,让多个用户都能使用 GPU 加速功能。使用 A100 40GB GPU,每个 MIG 实例最多可以分配 5GB,而随着 A100 80GB 增加的 GPU 内存容量,每个实例将增加一倍达到10GB。
A100 结合 MIG 技术可以更大限度地提高 GPU 加速的基础设施的利用率。借助 MIG,A100 GPU 可划分为多达 7 个独立实例,让多个用户都能使用 GPU 加速功能。使用 A100 40GB GPU,每个 MIG 实例最多可以分配 5GB,而随着 A100 80GB 增加的 GPU 内存容量,每个实例将增加一倍达到10GB。
MIG 与 Kubernetes、容器和基于服务器虚拟化平台的服务器虚拟化配合使用。MIG 可让基础设施管理者为每项作业提供大小合适的 GPU,同时确保服务质量 (QoS),从而扩大加速计算资源的影响范围,以覆盖每位用户。